reactNative 原理
说明:没有Andorid,ios,c++底层分析功力无法完全通透
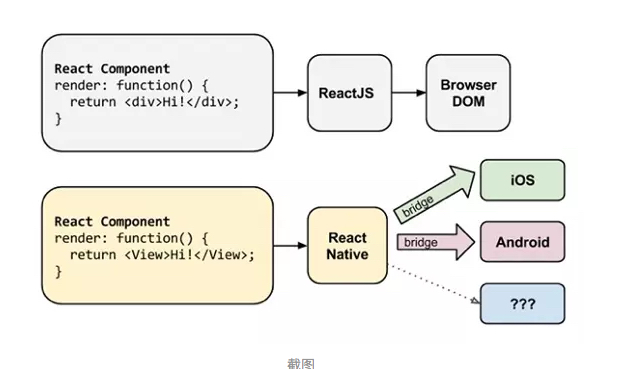
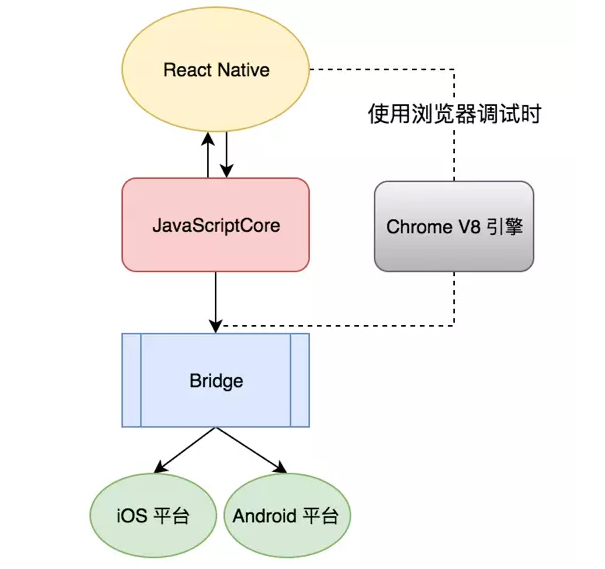
React Native 渲染
在 React 框架中,JSX 源码通过 React 框架最终渲染到了浏览器的真实 DOM 中,而在 React Native 框架中,JSX 源码通过 React Native 框架编译后,通过对应平台的 Bridge 实现了与原生框架的通信。如果我们在程序中调用了 React Native 提供的 API,那么 React Native 框架就通过 Bridge 调用原生框架中的方法。
JavaScriptCore是一个C++ vm。使用Apple提供的JavaScriptCore框架,你可以在Objective-C或者基于C的程序中执行Javascript代码,也可以向JavaScript环境中插入一些自定义的对象。JavaScriptCore从iOS 7.0之后可以直接使用。
因为 React Native 的底层为 React 框架,所以如果是 UI 层的变更,那么就映射为虚拟 DOM 后进行 diff 算法,diff 算法计算出变动后的 JSON 映射文件,最终由 Native 层将此 JSON 文件映射渲染到原生 App 的页面元素上,最终实现了在项目中只需要控制 state 以及 props 的变更来引起 iOS 与 Android 平台的 UI 变更。
编写的 React Native代码最终会打包生成一个 main.bundle.js 文件供 App 加载,此文件可以在 App 设备本地,也可以存放于服务器上供 App 下载更新,热更新就会涉及到 main.bundle.js 位置的设置问题。
- 优点:
1.复用了 React 的思想,有利于前端开发者涉足移动端
2.能够利用 JavaScript 动态更新的特性,快速迭代
3.相比于原生平台,开发速度更快,相比于 Hybrid 框架,性能更好
- 缺点
- 开发者依然要为 iOS 和 Android 两个平台提供两套不同的代。有组件是区分平台的,即使是共用组件,也会有平台独享的函数。
- 不能做到完全屏蔽 iOS 端或 Android端,前端开发者必须对原生平台有所了解。
- 由于 Objective-C 与 JavaScript 之间的切换存在固定的时间开销,所以性能必定不及原生。(比如目前的官方版本无法做到 UItableview(ListView) 的视图重用,因为滑动过程中,视图重用需要在异步线程中执行,速度太慢。这也就导致随着 Cell 数量的增加,占用的内存也线性增加。)
- React Native 交互原理总结
Objective-C 有 JavaScript Core 框架用来执行 JavaScript 代码。
JavaScript 通过配置表生成类,方法,参数三个元素,放入消息队列,Objective-C获取之后,
就可以唯一确定要调用的是哪个Objective-C函数,然后调用
babel 原理,抽象语法树如何产生?
- 将整个代码字符串分割成 语法单元 数组, 最小语法单元包含。
- 空白:JS中连续的空格、换行、缩进等
- 注释:行注释或块注释
- 字符串
- 数字 16、10、8进制以及科学表达法等数字表达语法
- 标识符,没有被引号括起来的的连续字符,包含字母,_,数字,常量 true,false,if , return, function
- 运算符 +、-、*、/、>、<
- 括号 ( ), 大扩招,冒号,分好,点,等等
拆分过程就是 一个字符一个字符地遍历,然后分情况讨论,整个实现方法就是顺序遍历和大量的条件判断。1
2
3
4
5
6if (1 > 0) {
alert("if \"1 > 0\"");
}
'if' ' ' '(' '1' ' ' '>' ' ' ')' ' ' '{'
'\n ' 'alert' '(' '"if \"1 > 0\""' ')' ';' '\n' '}'
1 | function tokenizeCode(code){ |
- 语义分析:在分析结果的基础上分析 语法单元之间的关系
在编程语言的解析中有两个很相似但是又有区别的重要概念:
- 表达式:每个表达式都会产生一个值,它可以放在任何需要一个值的地方
1 | var a = (5 + 6) / 2; //表达式:(5 + 6) / 2 |
- 语句: 是由“;(分号)”分隔的句子或命令。如果在表达式后面加上一个“;”分隔符,这就被称为“表达式语句”。它表明“只有表达式,而没有其他语法元素的语句”。
1
2
3
4
5
6
7
8
9
10
11
12var num = 9; //声明、赋值语句
vloop: //标签语句
{ //其实这里大括号可以不需要的,在这里我只想向大家展示一下这种代码块结构而已
for(var i=1; i<10; i++) { //循环语句
if(i==num){ //条件语句
break vloop;
}else{
num = num - 1;
}
}
}
console.log(num); //表达式语句,输出:5
1 | /* |
webpack 原理
实现一个简单的webpack link
1 | let mainFile = parse(config.entry, true) //babylon.parse 返回入口js文件的AST抽象语法树,依赖 |
DIFF 算法实现 原理
1 | import {StateEnums,isString, move } from ‘./util’ |
diff的不足与待优化的地方
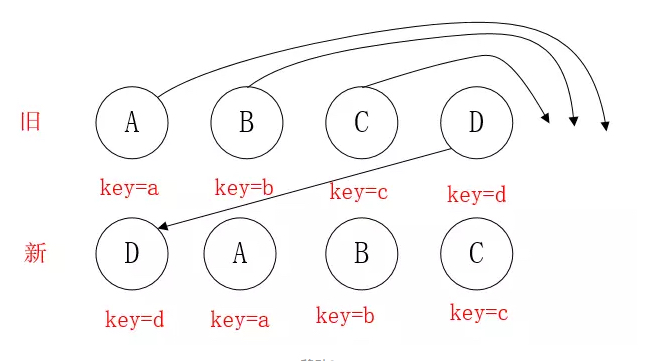
看图的 D,此时D不移动,但它的index是最大的,导致更新lastIndex=3,从而使得其他元素A,B,C的index<lastIndex,导致A,B,C都要去移动。
理想情况是只移动D,不移动A,B,C。因此,在开发过程中,尽量减少类似将最后一个节点移动到列表首部的操作,当节点数量过大或更新操作过于频繁时,会影响React的渲染性能。
viturl Dom实现
Virtual Dom实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75//创建节点
//实现逻辑:
1 创建一个el空节点,遍历props,添加为el属性,如果存在key属性,添加key属性到le上
2 判断child参数是否存在,迭代child,判断child的每项是虚拟El节点则递归创建节点方法,不是El节点肯定为Text节点,
创建Text文本节点。 最后统一插入到el空节点下, 递归完成返回el节点
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>
var ul = el('ul', {id: ‘list’,class:’list'}, [
el('li', {class: 'item'}, ['Item 1']),
el('li', {class: 'item'}, ['Item 2']),
el('li', {class: 'item'}, ['Item 3'])
],'key')
export default class Element {
/**
* @param {String} tag 'div'
* @param {Object} props { class: 'item' }
* @param {Array} children [ Element1, 'text']
* @param {String} key option
*/
constructor(tag, props, children, key){
this.tag = tag
this.props = props
if(Array.isArray(children)){
this.children = children
}else if(isString(children)){
this.key = children
this.children = null
}
if(key) this.key = key
}
render(){
let root = this._createElement(
this.tag,
this.props,
this.children,
this.key
)
document.body.appendChild(root)
return root
}
create(){
return this._createElement(this.tag,this.props,this.children,this.key)
}
//创建节点
//实现逻辑:
1 创建一个el空节点,遍历props,添加为el属性,如果存在key属性,添加key属性到le上
2 判断child参数是否存在,迭代child,判断child的每项是虚拟El节点则递归创建节点方法,不是El节点肯定为Text节点,
创建Text文本节点。 最后统一插入到el空节点下, 递归完成返回el节点
_createElement(tag,props,child,key){
let el = document.createElement(el);
for(let key in props){
value = props[key];
el.setAttribute(key,value)
}
if(key){
el.setAttribute(‘key’,key)
}
if(child){
child.foreach(elem=>{
if(elem instanceOf Element){
let els = _createElement(elem.tag,elem.props,elem.child,elem.key)
}else{
let els = document.createTextNode(textNode)
}
el.appendChild(els)
})
}
return el;
}
}
Vue-router路由原理
目前在浏览器环境中这一功能的实现主要有两种方式:
利用URL中的hash(“#”) HashHistory
特点:
- hash虽然出现在URL中,但不会被包括在HTTP请求中。它是用来指导浏览器动作的,对服务器端完全无用,因此,改变hash不会重新加载页面
- 可以为hash的改变添加监听事件: window.addEventListener(“hashchange”, funcRef, false)
- 每一次改变hash(window.location.hash),都会在浏览器的访问历史中增加一个记录
HashHistory中的push()方法:1
2
3
4
5
6
7
8
9
10push (location: RawLocation, onComplete?: Function, onAbort?: Function) {
this.transitionTo(location, route => {
pushHash(route.fullPath)
onComplete && onComplete(route)
}, onAbort)
}
function pushHash (path) {
window.location.hash = path
}
transitionTo()方法是父类中定义的是用来处理路由变化中的基础逻辑的,push()方法最主要的是对window的hash进行了直接赋值HashHistory.replace()
* replace()方法与push()方法不同之处在于,它并不是将新路由添加到浏览器访问历史的栈顶,而是替换掉当前的路由:
1 | replace (location: RawLocation, onComplete?: Function, onAbort?: Function) { |
利用History interface在 HTML5中新增的方法 HTML5History
pushState(), replaceState()使得我们可以对浏览器历史记录栈进行修改:
两者优劣
调用history.pushState()相比于直接修改hash主要有以下优势:
- pushState设置的新URL可以是与当前URL同源的任意URL;而hash只可修改#后面的部分,故只可设置与当前同文档的URL
- pushState设置的新URL可以与当前URL一模一样,这样也会把记录添加到栈中;而hash设置的新值必须与原来不一样才会触发记录添加到栈中
- pushState通过stateObject可以添加任意类型的数据到记录中;而hash只可添加短字符串
- pushState可额外设置title属性供后续使用
history模式的一个问题
比如用户直接在地址栏中输入并回车,浏览器重启重新加载应用等。
hash模式仅改变hash部分的内容,而hash部分是不会包含在HTTP请求中的:
http://oursite.com/#/user/id // 如重新请求只会发送http://oursite.com/
故在hash模式下遇到根据URL请求页面的情况不会有问题。而history模式则会将URL修改得就和正常请求后端的URL一样
http://oursite.com/user/id
解决:
在 Vue 应用里面覆盖所有的路由情况,然后在给出一个 404 页面。或者,如果是用 Node.js 作后台,可以使用服务端的路由来匹配 URL,当没有匹配到路由的时候返回 404,从而实现 fallback。
react使用一个叫做connect-history-api-fallback 中间件解决
小程序的实现原理是什么?
小程序架构 http://www.bubuko.com/infodetail-1906089.html
generator 原理
Generator 是 ES6中新增的语法,和 Promise 一样,都可以用来异步编程
1 | // 使用 * 表示这是一个 Generator 函数 |